多核心与并行概述
“Single core processors are a shrinking minority of all the processors in the world. Multicore processors, offering parallel computing, have displaced single core processors permanently. The future of computing is parallel computing, and the future of programming is parallel programming.”
---James Reinders from Intel
为英文不熟的同学翻译一下子:
单核处理器是处理器世界中正在不断缩减规模的少数群体。多核处理器因为能够提供并行计算,正在永久性地替代单核处理器的地位。未来的计算将是并行计算的天下,未来的编程亦将是并行编程的天下。
因为说这话的人是Intel的工程师,所以嵌入式系统的工程师听起来多多少少可能觉得未免危言耸听了。但是从过去几十年的科技发展经验来看,嵌入式系统的发展总是慢慢会跟随桌面计算,服务器计算的道路,只是稍稍慢那么一拍而已。考虑到硬件的发展速度终将不能以摩尔速度无限制的发展下去,多核与并行的概念引入在嵌入式系统中可能比大多数人预计的要更早一些吧。作者本人也觉得如同OS概念一样,多核与并行的概念在嵌入式系统上与桌面/服务器系统上仅仅只是规模上的差别,不存在本质的区别。
目前而言,作者认为嵌入式系统的多核与桌面/服务器系统地多核有以下显著的差别:
1、相对而言,嵌入式系统对运算的要求不是那么苛刻,所以数学运算方面的库函数暂时无需特别定制的并行版本;
2、因为嵌入式系统的多核心多采用Little+Big的非对称架构,故此一般有一个核心为主,其余核心都属于从,比较类似于协处理器的概念,但是与FPU等协处理器不同的是这些从核心自主性都很高;
3、因为上述的little+big的架构,故此任务的分配上从算法上来讲要简单一些,但是与硬件耦合较为紧密;所以目前桌面/服务器系统上的多核框架如OpenMP,OpenCL还不能简单的搬来利用;
4、操作系统中的thread概念一般被认为是并行编程的低级别并行,桌面/服务器系统中目前的趋势是抛弃thread这种低级操作,直接使用高级并行框架如OpenMP,Clik Plus等等将整个系统看作一个整体,由框架来分配任务。嵌入式系统对应thread的是各种RTOS的task,这种低等级的并行操作的标准度很低。所以如何将整个嵌入式处理器视作一个整体来隐式进行并行编程可能是最后完成的任务。
我们看一个例子:
1 #include <stdio.h>
2
3 int main(void)
4 {
5 #pragma ompparallel
6 printf("Hello,world.\n");
7
8 return 0;
9 }
10 //gcc -fopenmp omp_t1.c
这段代码在桌面计算机中以注释中的命令行build之后运行:
Hello, world.
Hello, world.
Hello, world.
Hello, world.
这是Open MP架构与工具链结合,将受控语句分别分配给四个核心(作者的实验电脑)运行。这个例子如果使用thread来做,创建多个thread,那么移植到嵌入式平台就好办了。但是由于硬件,OS,Library等等的不标准,目前在嵌入式系统的开发中做到如上述代码这样的自动化并行程度。
从上面的例子可以得知,嵌入式系统的并行计算还与桌面/服务器领域的发展趋势还有一大段距离。感兴趣的同学可以去自行了解一下子:Open MP, Open CL, Intel CLik Plus, MPI这几个项目。目前看来嵌入式平台的多核架构类似于操作系统的多个进程。作者还是从这个层面来做一些实验来展示相关的并行概念。
Practice: Mutex-资源互锁
PSoC 6的特点是双核心都能同时访问外设与内存。上一集的Demo正是两个内核分别控制LED进行闪烁。那么如果两个内核同时访问同一外设会怎样,比如UART。以下做个实验试验一下子。
首先在上次实验的基础上拖入一个UART来,直接从右边的工具盒子里面拖。
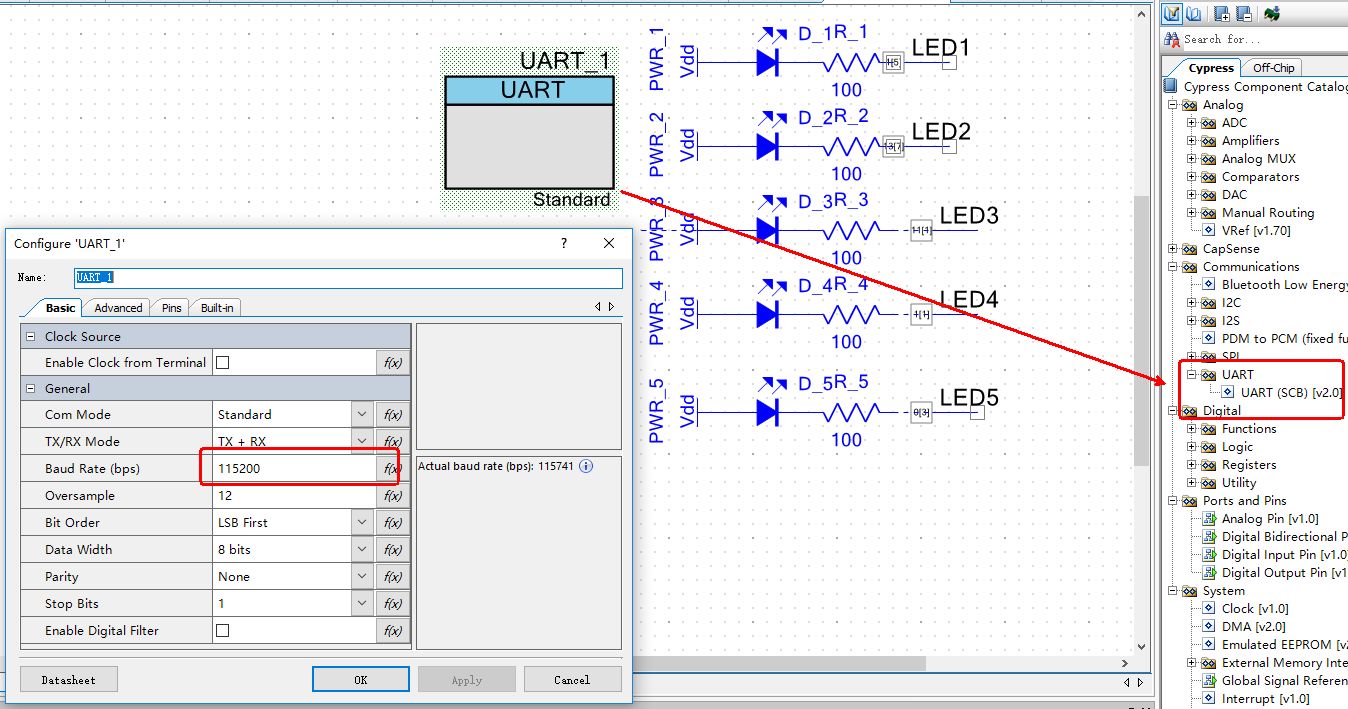
把波特率配置好之后,其余参数都用默认的。

用这个函数试验一下子简单的串口输出是否OK,过程不多讲:

确认串口工作之后,重定向STDOUT到串口,也就是要用printf做输出。(其实这实验直接使用底层串口输出函数也可以进行,只是重定向STDOUT这个以后要经常使用,顺带一题。)
因为本系列文章的例子都使用ARM-GCC工具链,故此只需要重写这个函数即可:
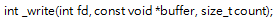
(注:PDL中也有Retarget的实现,兼容Keil MDK/IAR/GCC,但是如果只想使用printf,推荐使用本文的简单方法)
详细代码参见作者的git页面。
之后Cortex M0+与Cortx M4以如下流程运行:
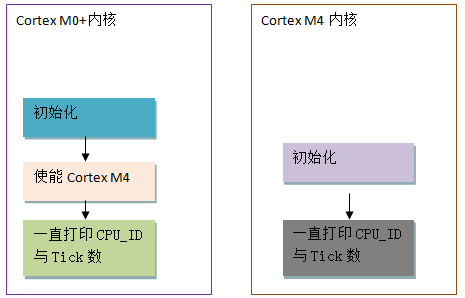
其中两者的打印代码段均为:

运行结果如下:
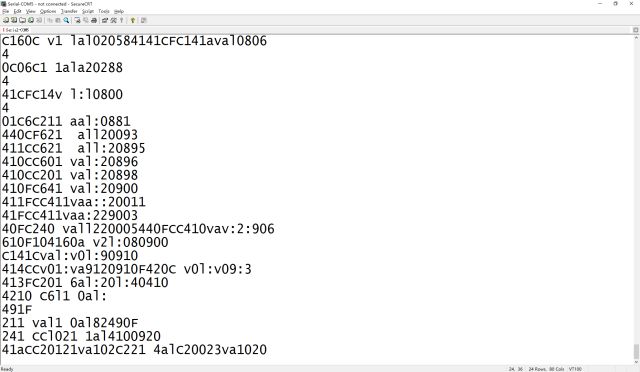
从结果可以看出来,双核心的打印全部穿插在一起了。看不出来原本的打印内容。发生这样的情况显然不是想要的结果。分析出现问题的根源在于:当前系统仅有的资源被多个核心使用而发生的争夺。
借鉴多进程编程的经验,可以得知解决这一问题的关键在于当某一核心使用该资源时,另外核心必须等待或者直接放弃。一般的做法是设定一定的等待时间,如果过了时间依旧获取不到该资源则进行超时退出等待。于是我们将上文的打印函数进行修改:
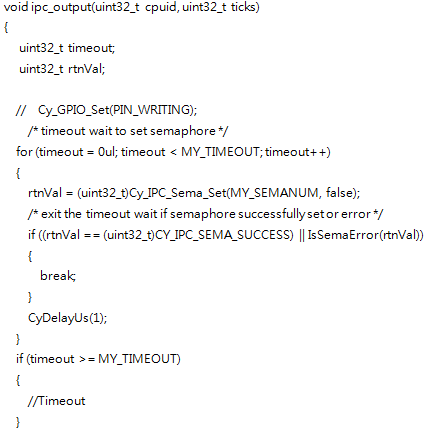

再次进行运行,结果如下:
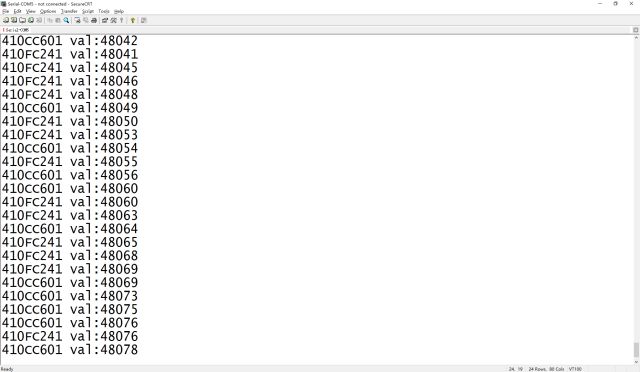
因为需要保护的资源要等到某一核心使用完毕之后才能被其他核心使用,这个过程不能被打断,所以称之为原子性操作。不管是多线程还是多核心,这个概念都类似.事实上嵌入式系统的程序员对这个概念并不陌生,ISR中与主循环中都需要修改的参数就必须以原子性操作来修改。

PSoC 6上的硬件IPC特性与PDL中的IPC接口
PSoC 6处理器中在硬件上就有对IPC的支持,此外PDL中也有详尽的IPC的驱动代码。PDL中的IPC驱动可以分为三部分:
驱动API:
最底层的API,事实上用户无需调用这个层的API。
文件:cy_ipc_drv.c, cy_ipc_drv.h
管道API:
用于内核之间建立管道进行较大的数据量传输。
文件:cy_ipc_pipe.c, cy_ipc_pipe.h
信号旗API:
用于内核之间同步状态,资源共享。上一章节的例子即是使用Semaphore来进行资源共享的。
文件:cy_ipc_sema.c, cy_ipc_sema.h
此外PDL中还包含有IPC的配置模版件:cy_ipc_config.c, cy_ipc_config.h,这两个文件会在每个使用了IPC的工程中拷贝一份以便该项目配置IPC功能。
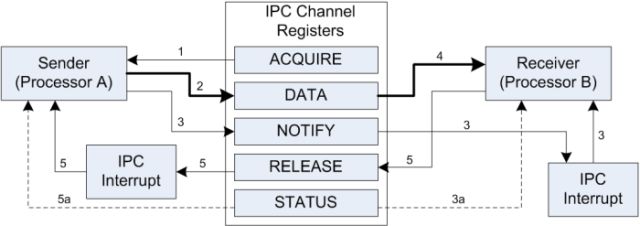
从硬件的角度来讲,IPC通信分5步走:
1. 发送的内核获取一个通道;
2. 将数据放入通道;
3. 发送内核产生一个通知中断;
4. 接收内核获取发送内核的标记并取走数据;
5. 接收内核产生一个释放中断。
从硬件上来讲,传输的数据最大为32bit的word,但是如果使用管道API,真正传输的数据为指向任意数据的指针。
管道层
管道层与桌面/服务器系统的管道十分类似,就是建立起一个双向的通信连接。每个管道有两个端点,每个端点位于不同内核,每个端点都有自己的通道与中断。
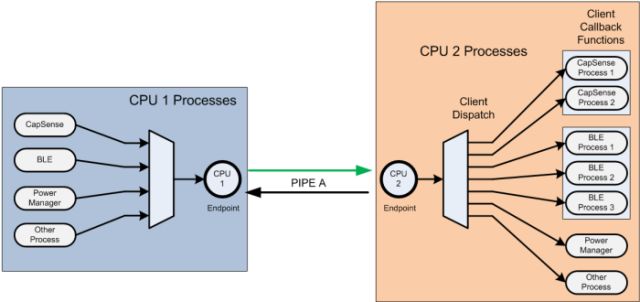
就PSoC 6双核处理器来讲,一共有16个IPC通道和相应的IPC中断。0-7的通道与中断留给系统用,其余给应用程序使用。
信号旗层
Semaphore就是上一章的例子使用的用来共享,同步资源使用的API。(另:Semaphore有很多种中文翻译版本,信号旗是作者认为最合理的翻译。)
这里把上一章的例子中的代码简要分析一下子:
要初始化Semaphore
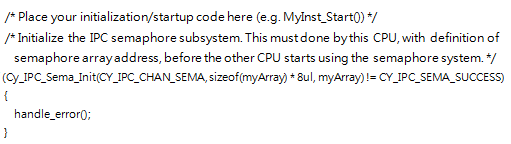
这里初始化的是128bit的semaphore,事实上这个大小只受SRAM大小的限制。注意多个内核中只能有一个内核运行这个函数,一般而言是Cortex M0+来运行这段代码。
之后获取Handle,以后的应用要使用:
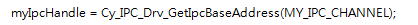
至此为止就可以唤醒另外一个内核了:
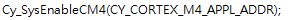
对于Cortex M4这边的初始化代码:
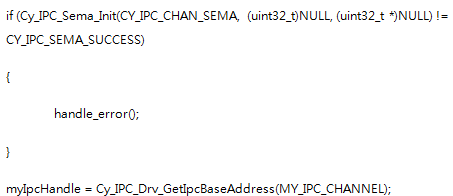
注意用来存储Semaphore的地址那里是空的,另外两边的通道号当然要是一样的。
这样两边都可以开始使用这个Semaphore了,具体如何使用代码请参考Github页面。
结论与资源
嵌入式系统多核心并行编程是个较新的话题, 作者对其理解还不深刻。文章肯定不少缺漏之处, 请读者多多指教。
另外本文所配的代码请点击下方阅读原文于此Git页面下载:
https://github.com/zhanzr/cy8ckit-demo.git
正在本文写作的期间,Cypress公司又推出了PSoC Creator 4.2的Beta 2版本,感兴趣的同学可以复制下方链接,下载看看新内容。
https://community.cypress.com/servlet/JiveServlet/downloadBody/14408-102...
上述Github中除了上述的Semaphore的例子之外,还有本人所作的双内核的Benchmark的程序.其中Dhrystone得分为:

为了便于比较,两个内核都设定为100MHz,因为这种评测并非能准确反映所评测内核的真实性能,故此仅仅作为参考,不做过多解读。相关代码,感兴趣的同学可以参考。
相关阅读:
(1)MCU中的奇美拉——Cypress PSoC 6 Pioneer Kit 系列评测之一
(2)低调的华丽——PSoC 6 BLE Pioneer Kit 评测系列之二
(3)PSoC 6 BLE Pioneer Kit 评测系列之三——电流检测功能
(4)PSoC 6 BLE PIONEER KIT专业评测之四——更灵活、更安全的低功耗物联网/可穿戴解决方案
本文转载自:Cypress
转载地址:http://mp.weixin.qq.com/s/rlmQLIG87bw2TJJaI6jMUw
声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有,如涉及侵权,请联系小编邮箱:cathy@eetrend.com 进行处理。