车辆检测技术看似神秘,本质上是通过数学公式,计算出图片上指定区域内的像素特征,进而根据特征判断物体所属类别。物体检测方法可以总结为特征提取与类别判定两步,常用方法为支持向量机,(Support Vector Machine,SVM)与方向梯度直方图(Histograms of Oriented Gradients,HOG)相互配合。

本文将从以下几个方面介绍这种常用的车辆检测算法,揭开其神秘面纱,也让读者通过阅读对机器学习过程有清晰的了解。
- 应用场景简介
- 详述HOG特征的计算方法
- 简述SVM的工作过程
- 对比及总结
01、应用场景简介
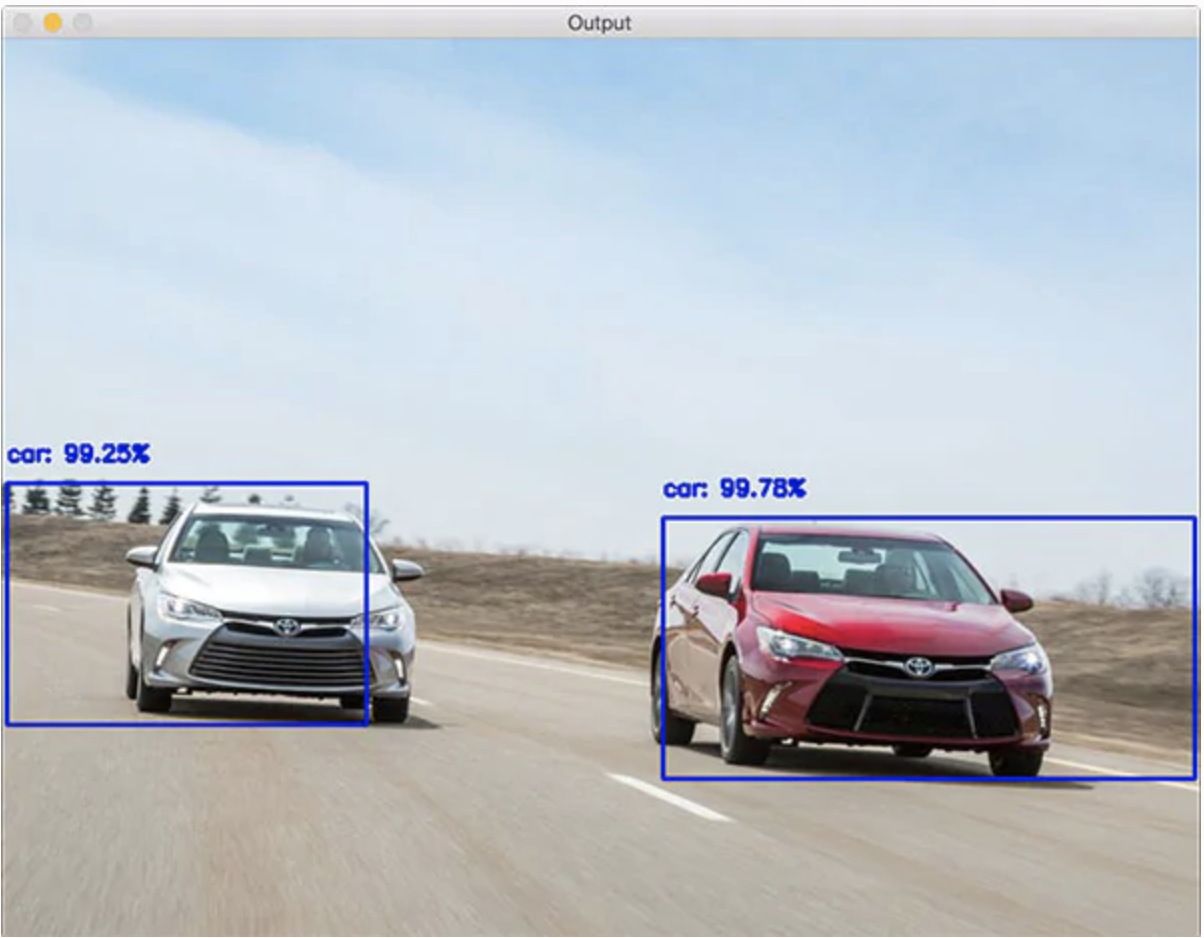
现实生活中车辆检测技术应用广泛,下面举例说明车内装置的应用。我们平时开的私家车里有时会有后置车载摄像头,后方一定距离内有车将要超过该车时,此系统便会启动,检测出后方车辆以后发出警报,提示驾驶员减速驾驶(图1)。另一个例子便是在自动驾驶领域的应用,通过对周边车的定位,分析他车车速、距离等干扰因素,从而改变该车的行驶轨道。
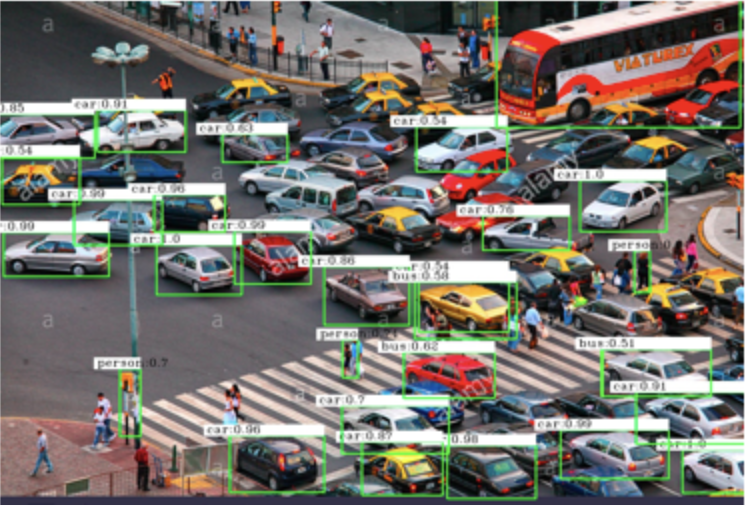
车辆检测系统还广泛用于交通管制和路况监控(图2),例如在隧道口安置此系统,就可以统计每天各个时段的车流量,适当实施限行政策,减少交通事故的发生,并且提醒驾驶员哪里是拥挤路段、哪里交通较为顺畅,进而方便驾驶员选择出行线路,起到疏散交通的目的。此外车流量的统计也会应用在机场或火车站的停车场,经过大数据分析出车位紧张的时段,以便工作人员合理调度资源。
附带车辆检测系统的信号灯可以通过与其他技术相结合,探测信号灯周围车流量,并由工作人员通过大数据人工智能进行统计,通过计算设定红绿灯交替变换的合理时间间隔。
HOG与SVM相结合的算法:(40−16)/8+1=4
利用HOG与SVM相结合的行人检测方法最初是由法国研究人员Dalal于2005年在CVPR上提出的,如今演变成以HOG+SVM为主要思路对各类物体进行检测,包括车辆以及车道的定位。
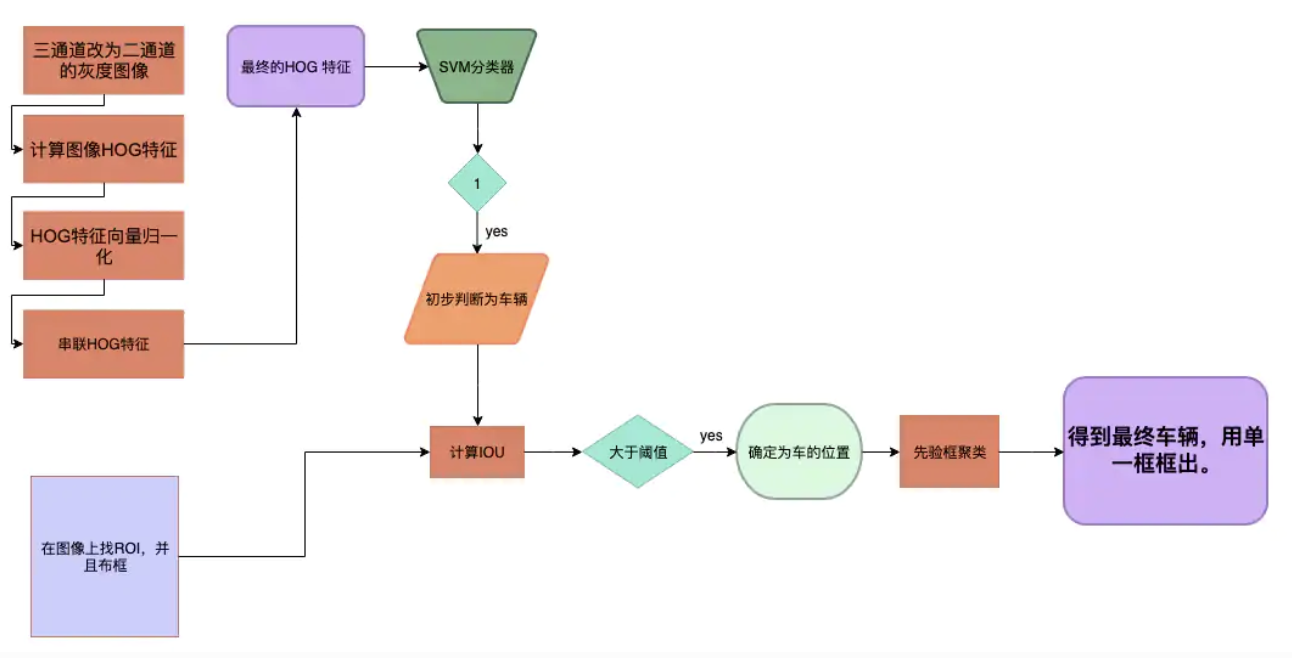
该方法步骤如下(图3)所示:
02、HOG特征计算
1. HOG是一个局部提取特征的算法。如果是包含复杂背景的大图,就算提取再多的特征也达不到检测物体的目的。我们需要将图片剪裁得到目标。经实验证明,车辆作为目标物体占图片比重必须大于80%才会得到好的效果。在剪裁好的局部图像上将图像分区(block),每个区域以细胞(cell)为单位提取特征。(图像中的多个像素为一个细胞cell,多个cell组成区域块block。)我们以图4为例,解释HOG特征的计算过程。首先剪裁得到一张40*40的图片(以像素为单位),之后我们要定义如下几个变量:
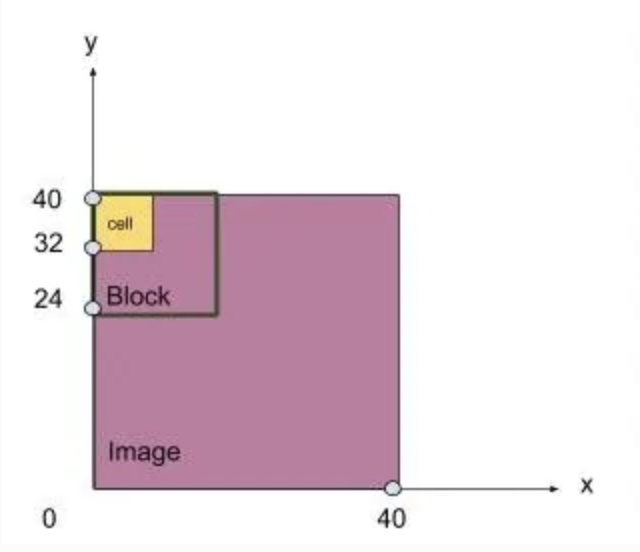
a、定义移动步长s,例如:s=1。
b、定义cell大小,以像素为单位,例如:8*8。
c、定义block大小,例如:由2*2=4个cell组成。
d、定义bin的数量取值,根据需要设定数量,例如bin=9,每个bin用来存放计算出的直方图的梯度方向累加值,其原理下文将具体讲解。
2. 对输入的图像及颜色进行标准化处理,减少光照或阴影对图像中物体检测准确性的干扰,具体做法是进行gemma颜色矫正后改为灰度图(Gemma颜色矫正原理在此不做介绍)。
3. 梯度大小的计算。以一个细胞部分区域为例做计算方法讲解(图5),下文为计算像素值为25的中间点的公式。
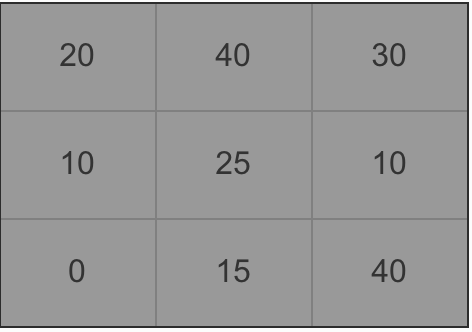
采用一个合理的卷积核方式的定义,实验表明[-1,0,1]效果最好。卷积核[-1,0,1]可以理解为一个矩阵,用于计算每个像素点的梯度幅值方向,因此我们可以横向(x轴正方向,向右)采用[-1,0,1]的卷积核,纵向(y轴正方向,向上)采用[-1,0,1]T,对于图像区域中的每一个像素点做横向、纵向的梯度分量计算,二者平方和开根号得到该点的梯度方向,因此计算公式如下:
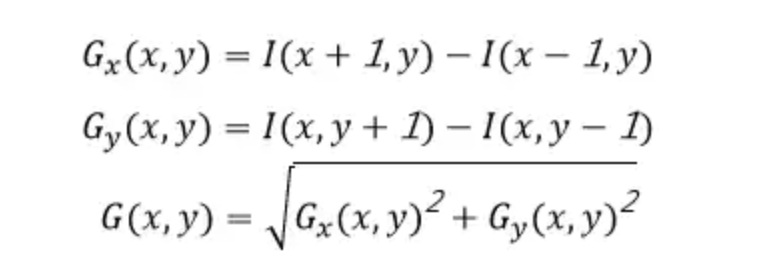
所以像素为25的点水平方向的计算方法如下(图6)所示:
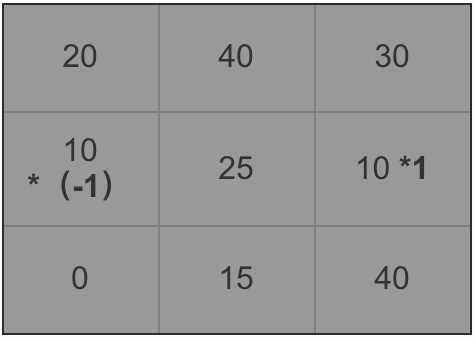
计算公式:
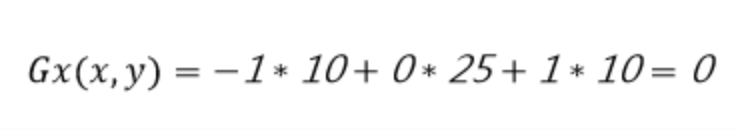
所以像素为25的点垂直方向计算方法如下(图7)所示:
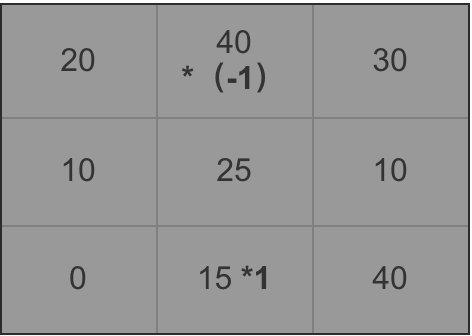
计算公式:
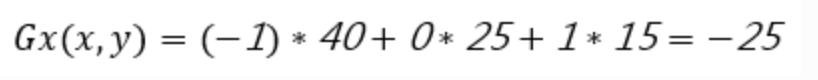
4. 梯度方向的计算采用以下公式:
5. 对每个细胞(cell)中的所有像素点重复3-4的计算过程,再将数值相加,我们就得到了一个细胞(cell)内9个梯度方向上的梯度积分图(图8)。
6. 求解图像分区(block)的HOG特征,即:将所包含的细胞(cell)特征串联到一起。
7. 求解整个图片的HOG特征,即:将所包含的图像分区(block)特征串联到一起。
8. 特征维度的计算方法:
以上例子中block块沿着x,y轴分别移动4步:
每个block中包含4个cell:
特征维度的计算公式:
因此该图例中通过计算得到特征维度是576。
9. 将求得的梯度向量正则化。正则化的重要目的是为了防止过拟合。过拟合会造成对训练集的分类效果过于理想,但是测试集检测率极其偏低,这显然是我们不能接受的。跟一般的机器学习特征正则化的道理相同,例如得到的特征值在(0,200)之间分布,我们要求防止200以内的数字对特征整体分布造成影响(模型在训练中会为了迎合200而偏离整体趋势,造成过拟合),因此要将特征分布规范化到一定区间。Dalal在论文中提到采用L2-norm得到的效果非常理想。(这里0,200指特征值所在的范围)
10. 将特征与标签一起送往SVM中对分类器进行训练。
直方图的梯度方向及bin的取值
Dalal在论文中提到,“这一步骤的目的是为局部图像区域提供一个指示函数量化梯度方向的同时,能够保持对图像中检测对象外观的弱敏感性”。梯度大小要根据梯度方向插入到对应的bin中,方向分为两种。第一种是无方向的方法(unsighed),适用于车辆或其他目标检测;第二种是有方向的方法(sighed),经实验证明,不适用于车辆或其他目标检测,这种方法在图片放大、缩小、或经过旋转后,像素点要恢复到原位置时会有应用,可以点击参考文献的第5个链接进行深入了解。
1. 无方向。(0,π)
下面我们详细了解无方向插值法。
本文将使用三张表格去做讲解,每张表格中第一行为计算出的幅值,第二行为规定好的bin的方向取值,由180度除以定义的bin个数得来。第三行为bin的序号,从0开始。
根据实际需要分成若干个bin,例如分成9个,即每个细胞内统计9个方向的梯度直方图,每个bin的覆盖方向为20度。将幅值(上文中计算的G(x,y))插入到bin中,最终bin中幅值的累加和即为直方图的纵轴,横轴则是bin的取值范围,该例中取(0,8)的数字。
插入值的方法:
若某个像素点的幅值为80,方向为20度,则插入到(表格1)蓝色区域的位置:
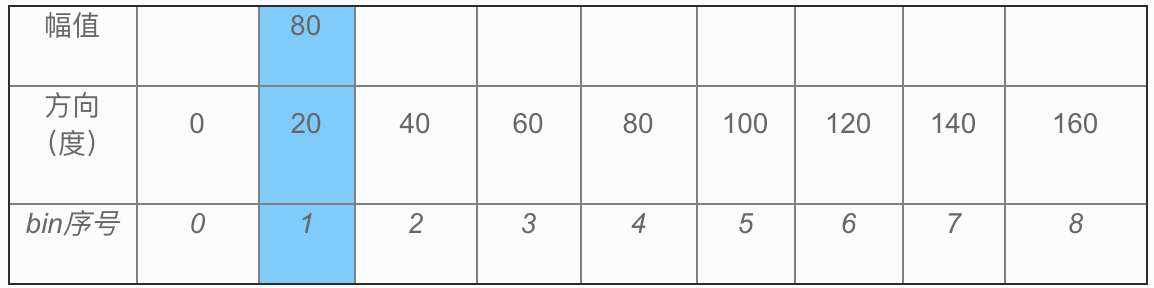
若幅值为80,方向为10度,则分别插入到(表格2)蓝色填充的两个位置:

若幅值为60,方向为165度,则分别插入到表格3蓝色的两个位置:
(180度和0度在方向上等价,所以幅值按1:3分别插入两个bin)
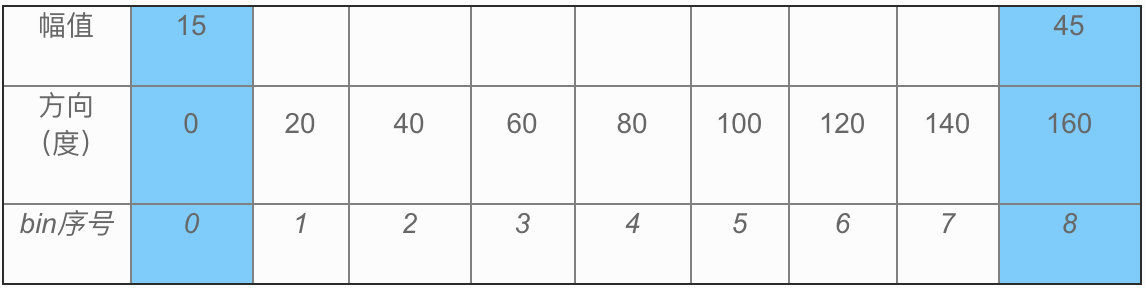
上述(表格1)介绍的方向值恰好为bin对应值的插入方法,表格2介绍了方向值介于两个bin值之间的插入方法,表格3介绍了方向值大于最大bin值的插入方法。根据三种方法的原理,以cell为单位计算,一个cell中所有像素点遍历后的幅值累加,例如上面我们在0号bin的位置得到了两个幅度值分别为40和15,因此我们到目前为止0号bin的直方图累加到55。以此类推,计算每个cell的1-8号bin幅度并分别累加。最终我们会得到类似于下面(图8)的直方图,其中横坐标X为梯度方向,纵坐标Y为梯度幅值:
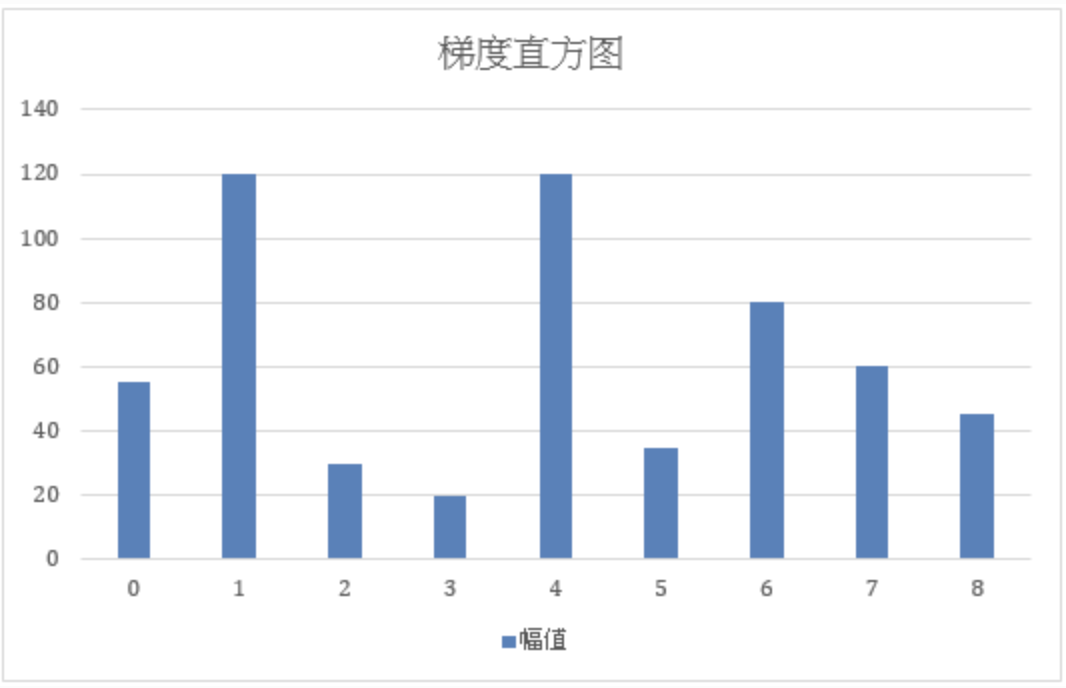
实验证明目标检测时用9个bin,单向插入会得到最佳效果。
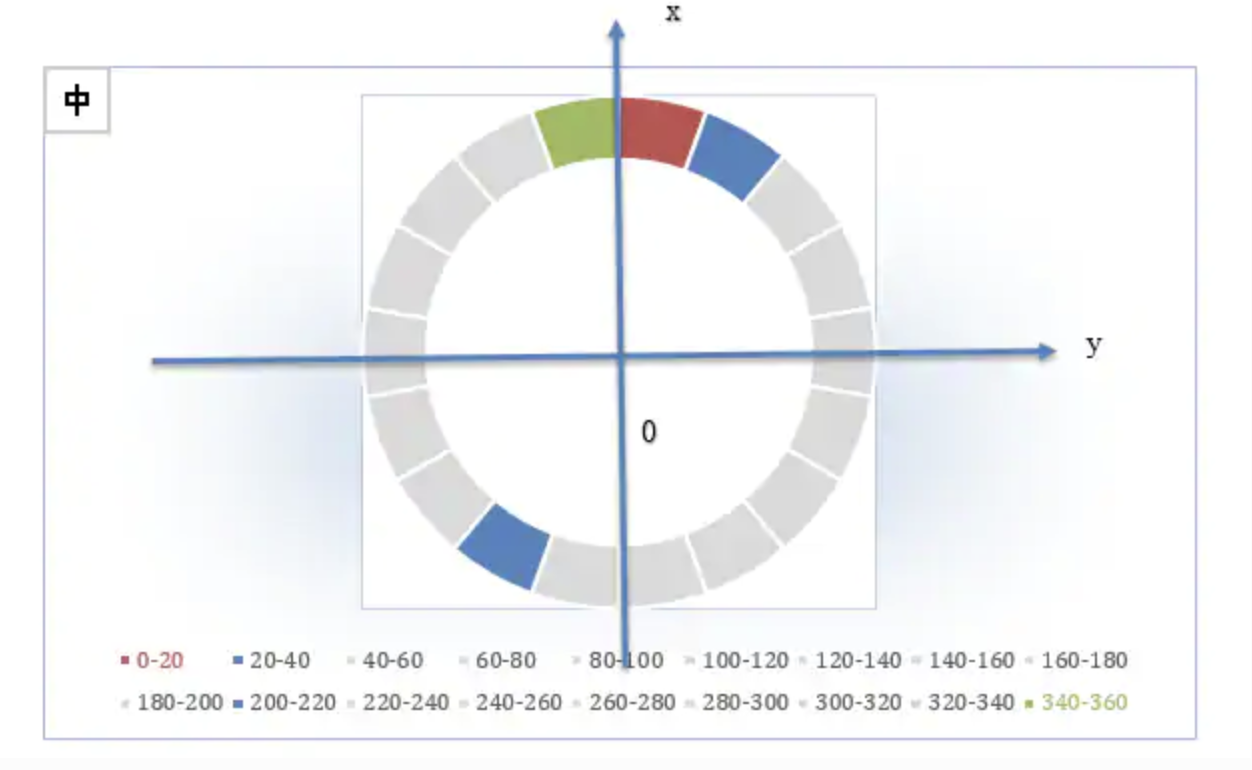
2. 有方向。(0,2π)
方向前加了正负号,若也定义9个bin,则每一个bin所分配到的角度范围是(0,π/9°)。例如,第二个bin的正值插入到20-40度的bin(蓝色的扇形区域),负值应插入到200-220度的bin中(蓝色的扇形区域)。(图9)
03、简述SVM的工作过程
SVM(Support Vector Machine)全称为支持向量机,在空间中就是将两个类别通过一个超平面分开,在二维空间可简单理解成为了找到y而y满足:
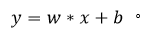
y的值决定了样本是正类还是负类。但是如何确定最优超平面,这里就引入了支持向量和最大间隔。我们的目标是引入超平面,使得距离超平面最近的点之间有最大间隔(图10)。
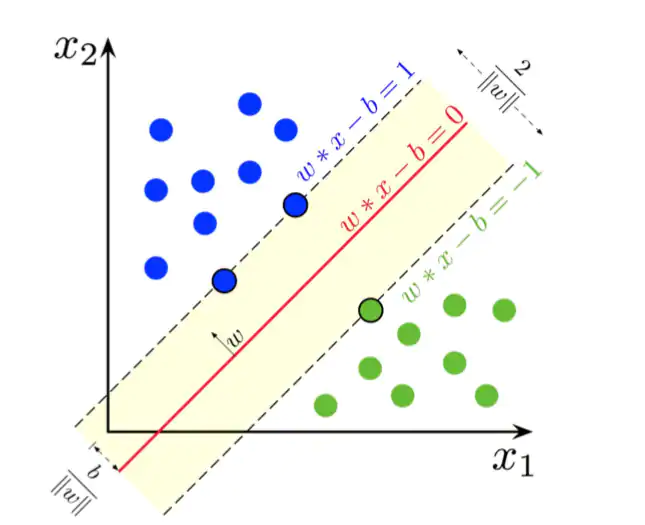
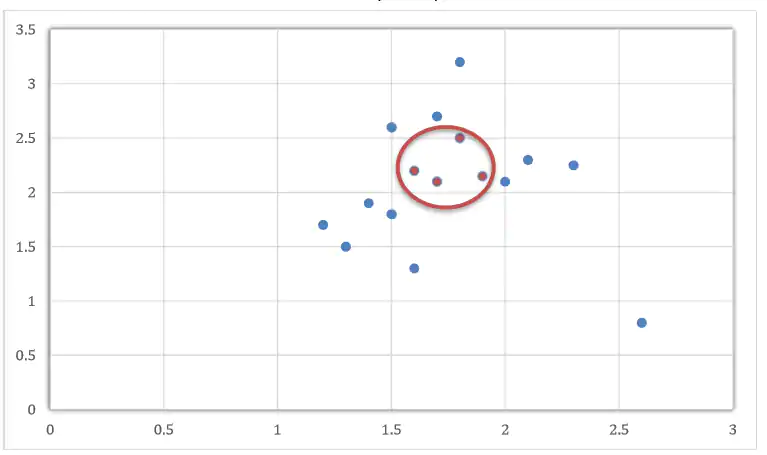
由于现实情况中的数据复杂度高,有时会根据需要引入核函数,作用是将低维度映射到高维度中,通过找到一个最优超平面使线性不可分(图11)的数据变得线性可分。
SVM的计算量大,训练耗时,因为对于每个点都要计算一遍与其他每一个点的相似度。因此SVM适用于数据量较小的二分类模型训练,若为多个类别,则通常分别训练多个模型。此外,台湾大学教授研发的两款开源工具当下深受科学家的喜爱,一个是LibSVM,另一个是基于SVM开发、适用于大数据量的liblinear。
SVM对参数也极其敏感。libSVM或LibLinear训练过程中要注意惩罚项C和权重系数W。C即惩罚项越大,代表训练过程分类效果越好,但是C过大会造成过拟合,即训练样本分类正确率极其高但是测试准确率极其低。数据中不可避免会出现一些远离集中群体的点,而C的大小表明了你是否愿意放弃这些离群点。越大表示越不愿意放弃,因此模型会特别好地拟合训练集而非测试集。W即权重代表正负样本的系数,如果想让更多的目标被检测出来,就将正样本权重加大,但是这样误检率(FP)会特别高。反之,负样本权重加大,就可以控制误检率(FP),当然目标检测率(TP)就会降低。
经过笔者亲自实验发现,一百万个数据,1152维特征,在2个CPU,60G内存的Windows10操作系统下,开18个线程训练耗时20分钟。因此作者建议大家使用liblinear库训练超大文本,或增加计算机内存。
04、对比及总结
本文重点解析了车辆检测的特征计算部分,以及简要介绍了SVM的分类策略。建议在将HOG特征用于车辆检测时,采用大于1000维度特征、9个bin的无方向插值法,特征分布不均匀务时必采用正则化处理;SVM可根据需要选择核函数,必要时可以选用LibSVM库训练基于超大数据量的模型。SVM的内核函数机制将低维度空间映射到高维度空间,有效解决了线性不可分的难题。SVM的计算复杂度由支持向量的个数决定,而幸运的是,最终决策函数只需由少量支持向量决定。SVM同样有其局限性。如果不使用LiBSVM/Liblinear开源库,单纯的SVM对大型数据的处理非常困难,因为SVM在计算过程中涉及矩阵计算,其行数列数由样本数量决定,而大型样本在计算过程中会消耗大量时间和空间。同理,在实践过程中,对于是否选择HOG也要双向考虑优缺点。这里对其优缺点做一个总结,以便读者参考:
优点:HOG是在局部的单元上做检测,能较好地捕捉局部形状信息,而忽略光照、色彩等因素,例如车辆检测中可以忽略车的色彩因素,从而降低所需要的特征维度,而且因为对光照的弱敏感度,即使车辆存在遮挡的部分也可以检测出。
缺点:HOG不擅长处理遮挡问题,车辆方向改变也不易检测;因为梯度的性质,HOG对噪点相当敏感,因此在实际应用中,在block和cell分割成局部区域单元之后,通常有必要做一次高斯平滑去除噪点。对特征维度的确定(细胞,块,步长的确定)要求高,实际工作中需反复设计方案实验得出最优解。
以上是本文的主要内容,希望给读者一个清晰的思路。尽管SVM与HOG的结合计算量大,但是成本较低,模型的训练也基于CPU就可以进行,深受中小型产品研发企业的青睐,例如车载摄像头等小部件的研发与产出,在保证可用性的前提下价格方面会亲民许多。
参考文献
https://blog.csdn.net/u011285477/article/details/50974230
https://www.learnopencv.com/histogram-of-oriented-gradients/
https://www.stat.purdue.edu/~panc/research/kernDescripObjReg/reference/2...
https://www.csie.ntu.edu.tw/~cjlin/libsvm/
https://blog.csdn.net/u011448029/article/details/11709443





