刚拿到STM32时,你只编写一个死循环

编译后,就会发现这么个程序已用了1600多的RAM,这要是在51单片机上,会心疼死了,这1600多的RAM跑哪儿去了,分析.map文件,你会发现是堆和栈占用的
在startup_stm32f10x_md.s文件中,它的前面几行就有以下定义:

这下明白了吧,STM32在启动的时候,RAM首先分配给使用到的全局变量,还有调用库占用的一些数据(不太清楚是什么数据),然后再将剩余的空间分配给Heap和Stack。由于内存空间是启动时实现分配好的,所以当动态分配内存的需求过多的时候,就会产生堆栈空间不足的问题。
查阅网上的资料,理解堆和栈的区别:
- (1)栈区(stack):由编译器自动分配和释放,存放函数的参数值、局部变量的值等,其操作方式类似于数据结构中的栈。
- (2)堆区(heap):一般由程序员分配和释放,若程序员不释放,程序结束时可能由操作系统回收。分配方式类似于数据结构中的链表。
- (3)全局区(静态区)(static):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后由系统自动释放。
- (4)文字常量区:常量字符串就是存放在这里的。
- (5)程序代码区:存放函数体的二进制代码。
例如:

所以堆和栈的区别:
- stack的空间由操作系统自动分配/释放,heap上的空间手动分配/释放。
- stack的空间有限,heap是很大的自由存储区。
- 程序在编译期和函数分配内存都是在栈上进行,且程序运行中函数调用时参数的传递也是在栈上进行。
显然 Cortex-m3资料可知:__initial_sp是堆栈指针,它就是FLASH的0x8000000地址前面4个字节(它根据堆栈大小,由编译器自动生成)
显然堆和栈是相邻的。
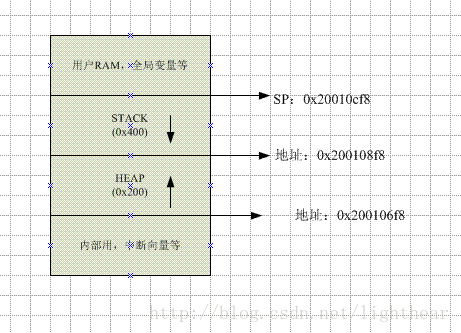
堆和栈空间分配:
- 栈:向低地址扩展
- 堆:向高地址扩展
显然如果依次定义变量,先定义的栈变量的内存地址比后定义的栈变量的内存地址要大,先定义的堆变量的内存地址比后定义的堆变量的内存地址要小。
堆和栈变量:
- 栈:临时变量,退出该作用域就会自动释放
- 堆:malloc变量,通过free函数释放
写程序时应该注意:
1. 所以最好是不要调用太深。
2. 局部变量不要太大太多,如局部数组,超过某个数量需定义为全局数组,因为局部数组同样储存在堆栈中。
本文转载自:lighthear的博客
转载地址:http://blog.csdn.net/lighthear/article/details/69568396
声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有,如涉及侵权,请联系小编进行处理。





